EKS Modernization with Karpenter for Auto-Scaling
Client / Industry
High-growth Digital Platform / SaaS (Consumer-facing, real-time analytics)
Client / Industry
High-growth Digital Platform / SaaS (Consumer-facing application)
Problem Statement
A high-growth digital platform running on Amazon EKS was experiencing unpredictable traffic spikes, leading to inefficient cluster scaling, elevated infrastructure costs, and performance bottlenecks during peak demand. The existing node group-based auto-scaling model lacked real-time responsiveness, resulting in: Over-provisioning during low traffic periods Delayed scaling during sudden spikes Suboptimal resource utilization The business required a real-time, cost-efficient, and intelligent auto-scaling solution capable of handling event-driven workloads without impacting user experience.
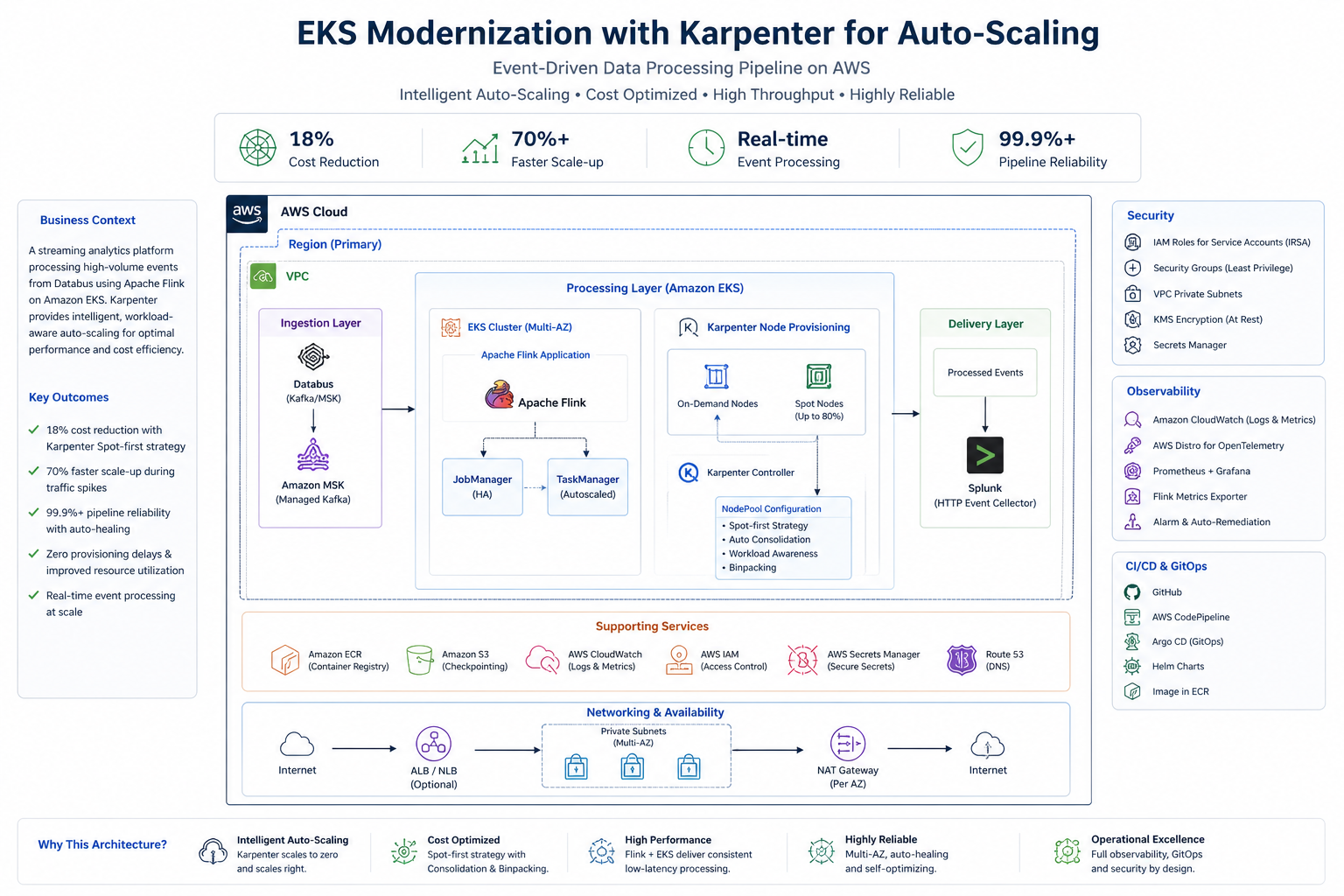
Architecture Overview
Led the modernization of an event-driven data processing platform by implementing Karpenter-based intelligent auto-scaling on Amazon EKS. Designed an end-to-end streaming architecture: Source: Databus (Kafka / Amazon MSK) Processing: Apache Flink on EKS Destination: Splunk (real-time ingestion via HTTP Event Collector) Replaced traditional node group scaling with Karpenter, enabling: Pod-driven, just-in-time node provisioning Faster and more efficient scaling decisions Elimination of idle capacity and scaling lag Implemented: Multi-AZ EKS cluster for high availability Spot-first compute strategy with On-Demand fallback IRSA for secure, fine-grained access control Private VPC architecture with controlled networking Centralized observability (CloudWatch, Prometheus, Flink metrics) Delivered a highly elastic, resilient, and cost-optimized streaming platform capable of handling dynamic workloads at scale.
AWS Services
Amazon EKS, Karpenter, Amazon EC2 (Spot & On-Demand), Amazon MSK (Kafka), AWS IAM (IRSA), Amazon VPC, Amazon CloudWatch, Prometheus, AWS Load Balancer Controller, Amazon ECR, Amazon S3 (Checkpointing), AWS Secrets Manager
Outcomes
18% reduction in infrastructure cost using Spot-first strategy with Karpenter ~70% faster scaling response time during traffic spikes Near real-time auto-scaling with zero manual intervention Reduced pod scheduling latency and improved performance Increased cluster utilization and minimized idle resources Enhanced system reliability with multi-AZ and self-healing architecture Seamless handling of burst workloads without degradation
Architecture Diagram